











Osez votre propre moteur de recherche !
Comme vous devriez le savoir, Google et bien d’autres sociétés ne tarissent pas de moyens pour collecter sur vous les moindres détails de votre vie. On peut au moins compter :
- IP
- liens de redirection avec ID personnalisée (avec Firefox, faites clic droit -> examiner sur un lien de résultat Google pour voir cette merde)
- cookie de Google.com mais aussi des services qui partagent leur données avec Google.com (Youtube, GooglePlus ,etc..)
- Flash variable, javascript et autre technique utilisant les fonctionnalités avancées de votre navigateur.
- HTTP referrer / user agent qui contient votre requête et des données sur votre configuration (OS, navigateur, résolution d’écran)
- services Google intégrés aux sites web que vous visitez après (Youtube, GoogleAnalytics, GooglePlus, etc…)
Beaucoup d’utilisateurs, réticents à ce qu’une société (ou la NSA pas loin derrière) puisse concentrer autant d’informations sur chaque humain se sont tourné vers DuckDuckGo comme moteur de recherche.
DuckDuckGo promet l’anonymisation de vos recherches. Mais quelle garantie offre ce discours de plus que le « Don’t be evil » de Google d’hier? Je n’ai aucun moyen de vérifier ce que fait DuckDuckGo de mes données, ni de vérifier si la NSA n’a pas un accès aux données de DuckDuckGo. De plus DuckDuckGo, utilise lui aussi un modèle économique basé sur la publicité pour financer ses coûts (Les fameuses « Instant answers » qui s’affichent avant tous les résultats et qu’on en peut pas désactiver) donc, ça va sentir le roussi bientôt pour avoir des réponses claires et pertinentes à ses requêtes.
En plus de cela, les résultats de DuckDuckGo sur plusieurs mots sont bien plus mauvais que ceux de Google.
Ma solution à cela est d’avoir son propre portail de recherche en local sur son ordinateur qui va faire le travail d’anonymisation pour nous. Voici à quoi ca ressemble :
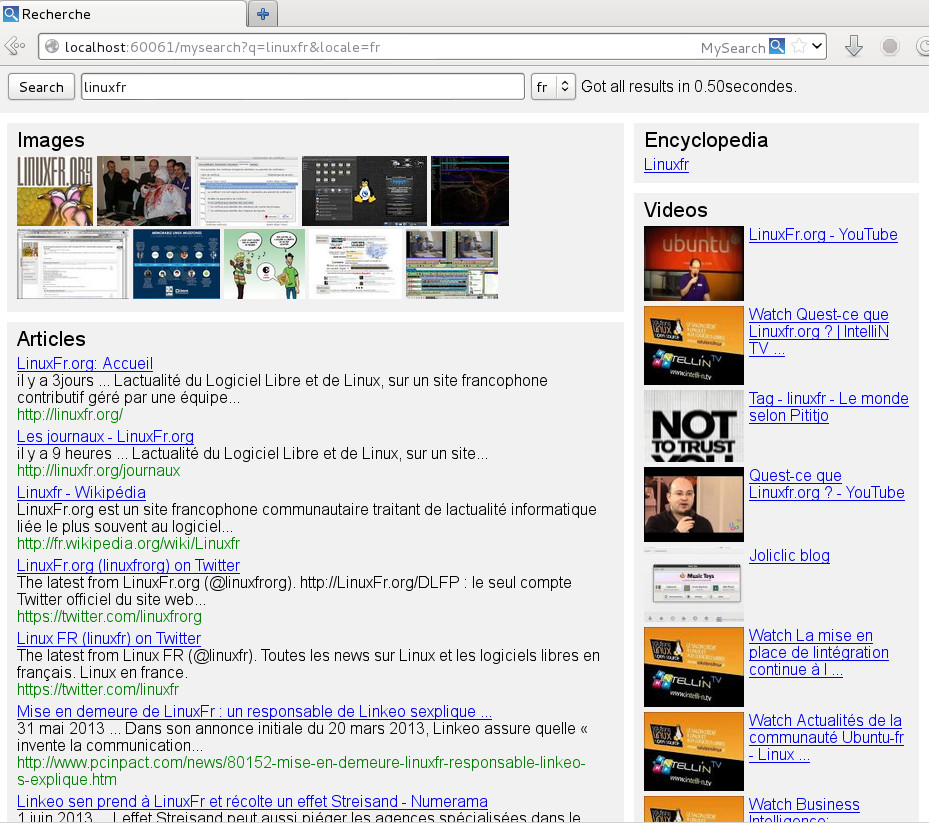
Sous le capot, il s’agit d’un petit programme local en Python/Twisted/Jinja qui va interroger différents moteurs de recherche par leur interface web (Startpage, Google, Wikipedia, etc…) et formater les résultats retournés dans une page web locale après anonymisation des liens.
Le formatage est fait par une simple feuille de style CSS. Facile de changer la mise en page.
Les requêtes aux différents moteurs de recherches sont dans des classes Python distinctes et il est facile de rajouter une recherche pour Bing, Yahoo, whatever…
Avantages :
- supprime toutes les publicités
- pertinence des résultats en provenance de ses moteurs de recherche préféré
- aucun cookie enregistré par les moteurs de recherche sur votre navigateur. (Donc pas de tracking par votre compte Google, Facebook, etc..)
- user-agent anonyme
- supprime les liens de redirection personnalisés qui nous identifient
- supprime le http-referrer lorsque l’on clique sur un lien de résultat
- permet de styliser l’apparence des résultats (ex: voir les résultats texte, vidéo, image et wikipedia en une seule page par exemple)
- permet de choisir sa source de recherche (Google, Ixquick; DuckDuckGo, Bing, etc…) sans changer de mise en page. (WIP)
- permet de choisir son pays de recherche (google.com, google.fr, etc…) sans changer de mise en page. En effet les résultats sont fortement différents selon la localisation de la requête.
- peut s’utiliser par l’interface OpenSearch (ajout à la liste des moteurs de recherches de Firefox par exemple)
Il reste encore un point à régler:
- anonymiser son IP lors de la collecte de résultats de recherche. Là c’est plus compliqué, il faudrait utiliser un proxy entre les utilisateurs du système pour brouiller les pistes. Ou n’utiliser que Startpage et DuckDuckGo comme source de resultats si on a confiance en eux pour ne partager notre couple IP/requête. Ou utiliser Tor.
Le dépôt du code est ici sous licence AGPL v3.
Pour tester chez vous :
$ sudo apt-get install python python-twisted python-jinja2 subversion
$ svn co http://svn.codingteam.net/mysearch
$ python mysearch/mysearch.py
Rendez vous sur http://localhost:60061
Comme DuckDuckGo au départ, ce système n’est pas un moteur de recherche classique avec un vrai crawler qui irait indexer toutes les pages du web. C’est trop coûteux. C’est donc pour l’instant un « meta-moteur » et les résultats proviennent de requêtes effectuées sur les moteurs existants.
J’ai essayé auparavant Yacy qui a un crawler mais ca consommait vraiment beaucoup de ressources (cpu, disque, réseau) pour des résultats pas forcément pertinents vu la faible puissance de calcul des utilisateurs du système.
J’ai essayé Seeks il y a longtemps, le projet est il mort? Le dernier post sur le site de projet donne des liens complètement cassés. Quoi qu’il en soit, le temps de réponse était long et je ne pouvait pas mixer les résultats aussi facilement que dans mon petit script Python.
Sur le modèle économique de la chose, on pourrait dire que je vole le travail effectué par Google en pompant ses résultats sans lui donner la monnaie de la pièce (je n’affiche pas ses publicités ni lui donne d’information personnelle). DuckDuckGo achète ses résultats à Yahoo et Bing (pour ceux qui pensaient que c’était gratuit) et bien entendu Google ne va pas lui vendre les siens.
Néanmoins, on peut aussi voir cela comme un post-traitement en local des données, au même titre que Adblock filtre la pub dans les pages web en local.
Ou aussi que si Google diffuse bien des extraits de mes pages (images, texte) sans que je ne puisse le contraindre à diffuser l’intégralité de mes pages, je peux bien faire de même et afficher des extraits de ses pages également. Si il n’est pas content, il n’a qu’à bannir mon IP (on va rire vu le nombre de machines qui risque que d’être derrière :D )

